



Data Science beschleunigt die Welt.
Wir synchronisieren Ihr Unternehmen.

31.03.2023 | Maschinelles Lernen
Von Wörtern zur Bedeutung: Wie Word Embeddings die Sprachverarbeitung revolutionieren
ChatGPT und andere moderne Machine Learning-Modelle sind gerade in aller Munde. Eine Grundlage, die diese Modelle benutzen sind sogenannte „Word Embeddings“. Damit Maschinen mit Texten und Wörtern arbeiten können, müssen diese in Zahlen umgewandelt werden. Die Grundidee des Ganzen haben wir bereits in einem anderen Journal-Beitrag zum Thema Bag-of-Words vorgestellt.
Wie im Journal-Beitrag schon angedeutet, gibt es deutlich bessere Methoden als Bag-of-Words, um Wörter und Texte in Vektoren umzuwandeln. Das größte Problem von Bag-of-Words ist, dass die Vektoren sehr groß werden, wenn viele Texte verarbeitet werden sollen.
Ganz anders sieht es bei Word Embeddings aus. Hier werden zwar auch Texte in Vektoren umgewandelt, der Unterschied ist jedoch, dass hier jedes einzelne Wort eines Textes durch einen Vektor dargestellt wird. Jeder Vektor ist allerdings deutlich kleiner und unabhängig davon, wie viele Texte verarbeitet werden. Wir können Sätze also auch bei sehr vielen verarbeiteten Texten durch eine Reihe kleiner Vektoren darstellen und benötigen dadurch weniger Zahlen als bei Bag-of-Words. Außerdem fangen diese Wort-Vektoren die Bedeutung der Wörter ein. So werden zum Beispiel Synonyme durch ähnliche Vektoren ersetzt.
Wie sieht das Embedding eines Wortes aus?
Die Größe der Vektoren lässt sich bei Word Embeddings festlegen und liegt häufig zwischen 50 und 500. Hier siehst Du ein Beispiel, wie so ein Vektor aussehen kann:
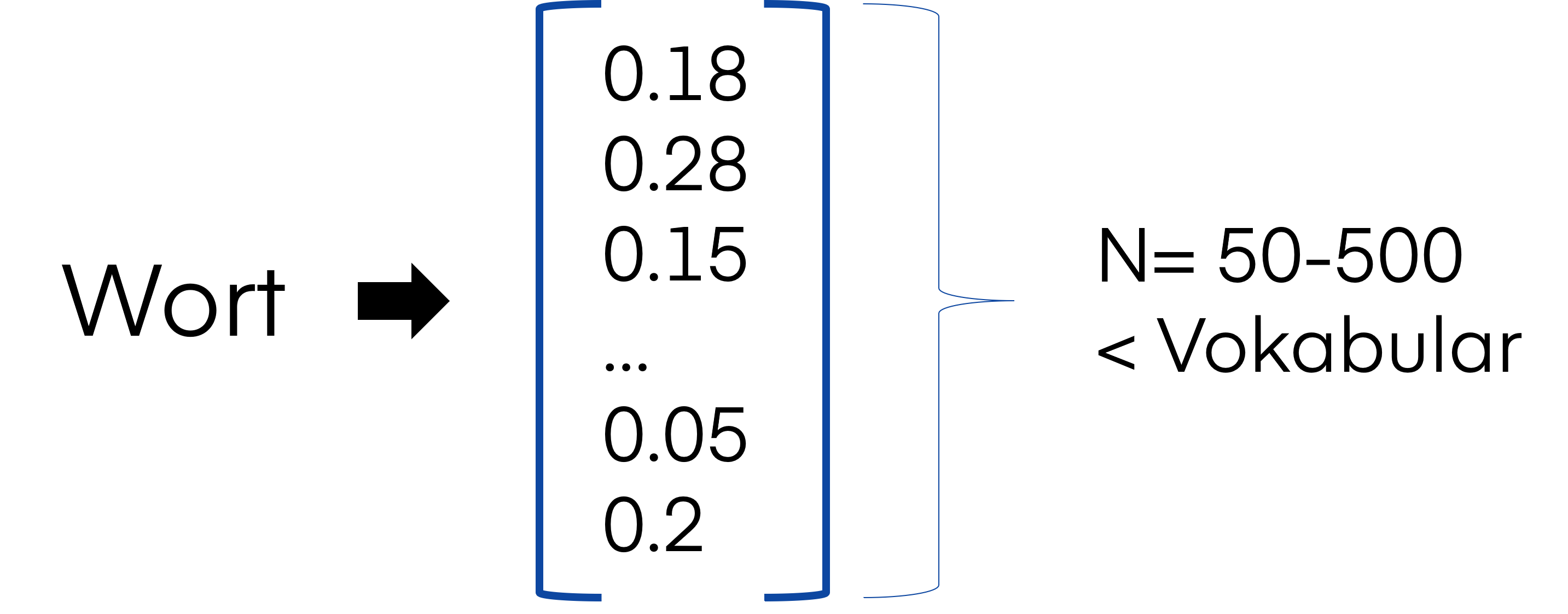
Da die Vektoren, wie bereits erwähnt, auch Wortbedeutungen einfangen, werden beispielsweise die Vektoren von „Unternehmen“ und „Firma“ sehr ähnlich sein. Machine Learning-Modelle machen sich dies zunutze und können Gelerntes von einem Wort auf das andere übertragen.
Schauen wir uns mal ein sehr bekanntes Beispiel an. Dabei geht es um Länder und ihre Hauptstädte. In der Abbildung unten sind die Vektoren auf zwei Dimensionen reduziert, um diese einfacher darstellen zu können.

Quelle: https://wiki.pathmind.com/images/wiki/countries_capitals.png
In der Abbildung kannst Du sehen, dass alle Hauptstädte auf einer Achse sehr nah beieinander liegen und sich sehr ähnliche Werte auf der x-Achse teilen. Das gilt auch für die Länder. Schaust Du Dir aber die y-Achse an, siehst Du, dass hier die Länder und ihre zugehörigen Hauptstädte sehr ähnliche Werte haben. Es werden also nicht nur Synonyme sehr ähnlichen Vektoren zugewiesen, sondern auch semantische Zusammenhänge erfasst.
Mit diesen Vektoren lässt sich sogar rechnen:
vec(“Paris”) – vec(“France”) + vec(“Germany”) ≈ vec(“Berlin”)
In der Praxis funktioniert das „exakte“ Rechnen zwar nur in sehr wenigen Fällen, solche Wortzusammenhänge werden jedoch intrinsisch auch vom Modell eingefangen.
Wie entsteht Wortbedeutung? – Ein Ausflug in die Linguistik
Um ein Gefühl dafür zu bekommen, welches Potenzial in Embedding-Verfahren steckt, lohnt sich ein Ausflug in die Linguistik. Wie entsteht eigentlich die Bedeutung eines Wortes? Diese Frage zu beantworten, ist nicht einfach und es ist ein stark diskutiertes Thema in der Linguistik. Es gibt (etwas vereinfacht) zwei konkurrierende Theorien:
1. Die Bedeutung eines Wortes entsteht dadurch, in welchem Kontext ein Wort in Texten (und Sprache) verwendet wird und durch generelles Allgemeinwissen über die Welt, in der wir leben.
2. Wir benötigen das Allgemeinwissen nicht. Der Kontext, in dem ein Wort verwendet wird, ist ausreichend, um die Bedeutung zu erfassen.
Es ist also nicht klar, ob wir Allgemeinwissen benötigen, um die Bedeutung von Wörtern zu erfassen oder nicht. Das es jedoch sehr schwer ist, einem Machine-Learning-Modell Allgemeinwissen beizubringen, es aber gleichzeitig sehr schnell, sehr viele Texte lesen kann, basiert das Training von Embeddings auf der zweiten Theorie. Auch wenn es nicht klar ist, welche Theorie stimmt, zeigt die Diskussion schon, dass wir durch den Verwendungskontext sehr viel über die Wortbedeutungen lernen können und mehr als nur oberflächliche Zusammenhänge erfassen.
Wie werden Embeddings trainiert?
Es gibt viele verschiedene Methoden Embeddings zu trainieren. Alle haben jedoch eine gemeinsame Grundidee, die wir Dir kurz anhand eines Beispiels erklären wollen:

Initial wird jedem Wort ein zufälliger Vektor von Zahlen zugewiesen. Diese Vektoren sind noch nicht hilfreich und bieten keine Informationen. So sind „faulen“ und „schnelle“ nicht sehr ähnliche Wörter, haben in dem Beispiel aber ähnliche Vektoren:

Im nächsten Schritt schaut sich das Embedding-Verfahren nacheinander Texte an und geht sie Wort für Wort durch. Das Verfahren verschiebt die Vektoren der Wörter in jedem Schritt ein wenig in die Richtung der Vektoren der Wörter, die im Kontext betrachtet werden. Betrachten wir also das Wort „Katze“ und verwenden für unser Beispiel einen Kontext von zwei Wörtern vor und nach dem betrachteten Wort:

Der Vektor dieses Wortes wird ein wenig in Richtung „schnelle“, „schwarze“, „springt“ und „über“ verschoben:

Wenn wir das für ganz viele Texte (in der Praxis sind dies häufig Millionen von Sätzen) machen, strukturieren sich die Vektoren nach und nach. Wenn in den Texten also viele ähnliche Sätze zu unserem Beispiel sind, ergibt sich folgende Struktur:

Jetzt haben wie die finalen Vektoren der Wörter und können einen Zusammenhang zwischen der „Katze“ und „schnell“, „schwarze“, „springt“ und „über“ erkennen.
Was jedoch bis hierhin noch nicht klar wird ist, warum Wörter mit ähnlichem Kontext ähnliche Vektoren bekommen. Da Synonyme in der Regel nicht zusammen in den gleichen Sätzen verwendet werden, werden diese auch nicht direkt aufeinander zu bewegt. Indirekt passiert das jedoch trotzdem. Um das zu veranschaulichen, betrachten wir einmal das Wort „Stubentiger“. Es ist ein Synonym für Katze und kann somit anstatt des Wortes „Katze“ verwendet werden. Es kommt deshalb aber nur sehr selten in den gleichen Sätzen wie das Wort „Katze“ vor und die Vektoren von „Katze“ und „Stubentiger“ werden nicht direkt aufeinander zubewegt. Dadurch, dass diese beiden Wörter aber in ganz ähnlichen Sätzen vorkommen, geschieht das indirekt:

Wenn dieser oder ähnliche Sätze ebenfalls häufig in Texten vorkommen, wird auch das Wort „Stubentiger“ in Richtung der Wörter „schnell“, „schwarze“, „springt“ und „über“ verschoben. Stubentiger und Katze haben also einen ähnlichen Kontext, der vom Modell erkannt wird. Insgesamt bekommen also Wörter mit einem ähnlichen Kontext auch ähnliche Vektoren:

Moderne Embedding-Methoden
Jetzt weißt Du schon einiges über die grundlegende Funktionalität von Word Embeddings. Mit der Zeit haben sich jedoch einige Optimierungen ergeben, die wir Dir natürlich nicht vorenthalten wollen.
Ein Problem der ersten Embedding-Modelle war es, dass nur Wörter eingebettet werden konnten, die auch in den Trainings-Texten vorhanden waren. Deshalb erstellen neuere Methoden nicht nur Embeddings für Wörter, sondern auch für Buchstabenfolgen, die häufig in den Texten vorkommen, bis hin zu Embeddings von einzelnen Buchstaben. Der Vektor für ein unbekanntes Wort kann dann durch die Vektoren der Buchstabenfolgen berechnet werden. Das funktioniert erstaunlich gut und trägt auch dazu bei, dass der Chat-Bot ChatGPT in der Lage ist, Wortneuschöpfungen zu kreieren.
Ein weiteres Problem war, dass Sprache häufig uneindeutig ist. So hat das Wort „Bank“ in den Sätzen „Ich setze mich auf die Bank.“ und „Ich raube die Bank aus.“ eine völlig andere Bedeutung. Deshalb können modernere Embedding-Verfahren auch den Kontext eines Wortes mit beachten und dem Wort „Bank“ zwei unterschiedliche Vektoren geben, die je nach Kontext verwendet werden.
In der natürlichen Sprache ist es jedoch häufig so, dass die wichtigsten Kontext-Wörter nicht neben dem betrachteten Wort stehen: „Die Katze, die gerade den faulen Hund entdeckt hat, springt über ihn.“ Moderne Embedding-Methoden lernen deshalb zusätzlich, welche Wörter die wichtigsten Kontext-Wörter sind und nutzen das, um die Wort-Bedeutungen effizienter und besser zu lernen.
Die neue Welt der automatisierten Textanalyse
Die grundlegende Idee von Word Embeddings ist so simpel wie genial und hat uns eine neue Welt im Bereich der automatisierten Textanalyse eröffnet. Word Embeddings sind die Grundlage für fast jedes komplexere Machine Learning-Modell, das mit natürlicher Sprache arbeitet. Mit der Veröffentlichung des Chatbots ChatGPT spricht nun auch die halbe Welt darüber, wie gut Machine Learning-Modelle mit Sprache umgehen können. Word Embedding ist einer der zentralen Bausteine des Chat-Bots, ohne den das alles nicht möglich wäre – ein durchaus mächtiges Verfahren also, dass auch in unseren Projekten häufig zum Einsatz kommt.
In unserem nächsten Beitrag wollen wir ein wenig tiefer in die wirkliche Anwendung von Embeddings eintauchen. Dann zeigen wir Dir, wie Du Topic Modelling mit Hilfe von Embeddings verbessern kannst. Es bleibt also spannend …

Ihr Ansprechpartnerin:
Sina Daba
Marketing Managerin
Data-Science-News direkt in Ihr Postfach
Sobald wir einen Beitrag in unserem Blog veröffentlichen, schicken wir Ihnen gerne eine E-Mail. Und keine Sorge – wir mögen auch keinen Spam!
„*“ zeigt erforderliche Felder an
Weitere interessante Beiträge aus der Kategorie: Maschinelles Lernen

Auf der Datenwelle
Link zu: Webinare
März & April 2026
Power BI in zwei Akten: Einstieg & Feature-Deep Dive
In zwei Webinaren zeigen wir Ihnen die Power BI-Basics für Marktforschungsdaten und verraten unsere Lieblings-Features.
Folge einem manuell hinzugefügten Link
VERGANGENE WEBINARE
Vom Datensammeln zum Consulting
Ein Webinar darüber, wie Hassia mit Dashboards abteilungsübergreifend den Umgang mit Daten verändert



